



Confluent offers Confluent for Kubernetes (formerly Confluent Operator) with its Enterprise licence. While Kubernetes is great for running cloud-native stateless workloads, companies have been increasingly implementing their data solutions on Kubernetes, too. For Confluent, it is important to provide a serverless experience of Apache Kafka to its users. It is challenging to implement a distributed stateful system like Kafka as a serverless offering. This brings up issues like expanding and contracting clusters elastically without any downtime, keeping the storage in the cluster balanced, etc. To achieve this, Confluent uses Kubernetes.
StatefulSets
To run its Brokers and Zookeeper, Confluent uses StatefulSets, which are like Kubernetes Deployments, except that the StatefulSet is designed to run stateful workloads. They key difference between stateless and stateful workloads is that while a stateless workload can be replicated to multiple instances, each of which do the same thing, instances of stateful workloads though, must have sticky identities. For example, pods of a database cannot afford to be identical because while they can all perform read operations, they cannot commit writes all at once - doing so would result in inconsistent data (violating the Consistency principle of ACID transactions.)
So, the pods that Deployments spin up are identical to each other, but pods brought up by a StatefulSet cannot be identical - they are ordered. A Deployment's pods have names with random hashes at the end but the names of a StatefulSet's pods have appended to them ordinal numbers that define a 0th pod, 1st pod, etc. Pods of a StatefulSet start up and shutdown sequentially. The 0th pod must come to a ready and running state before the 1st pod is started. They also have a sticky identity so when a pod dies, it gets replaced by a new pod with the same identity and with the same Persistent Volume Claim.
Confluent for Kubernetes uses StatefulSets for Kafka brokers and the Zookeeper.
Confluent Operator
In order to allow users to manage Confluent Platform, Confluent for Kubernetes exposes custom resources that it has defined, and implements the Operator pattern employed by Confluent Operator. Managing stateful applications in Kubernetes without a Kubernetes operator is tricky since the Kubernetes orchestrator does not know how to start up, update and shutdown the instances of the application. The operator pattern effectively automates the work of a devops operator.
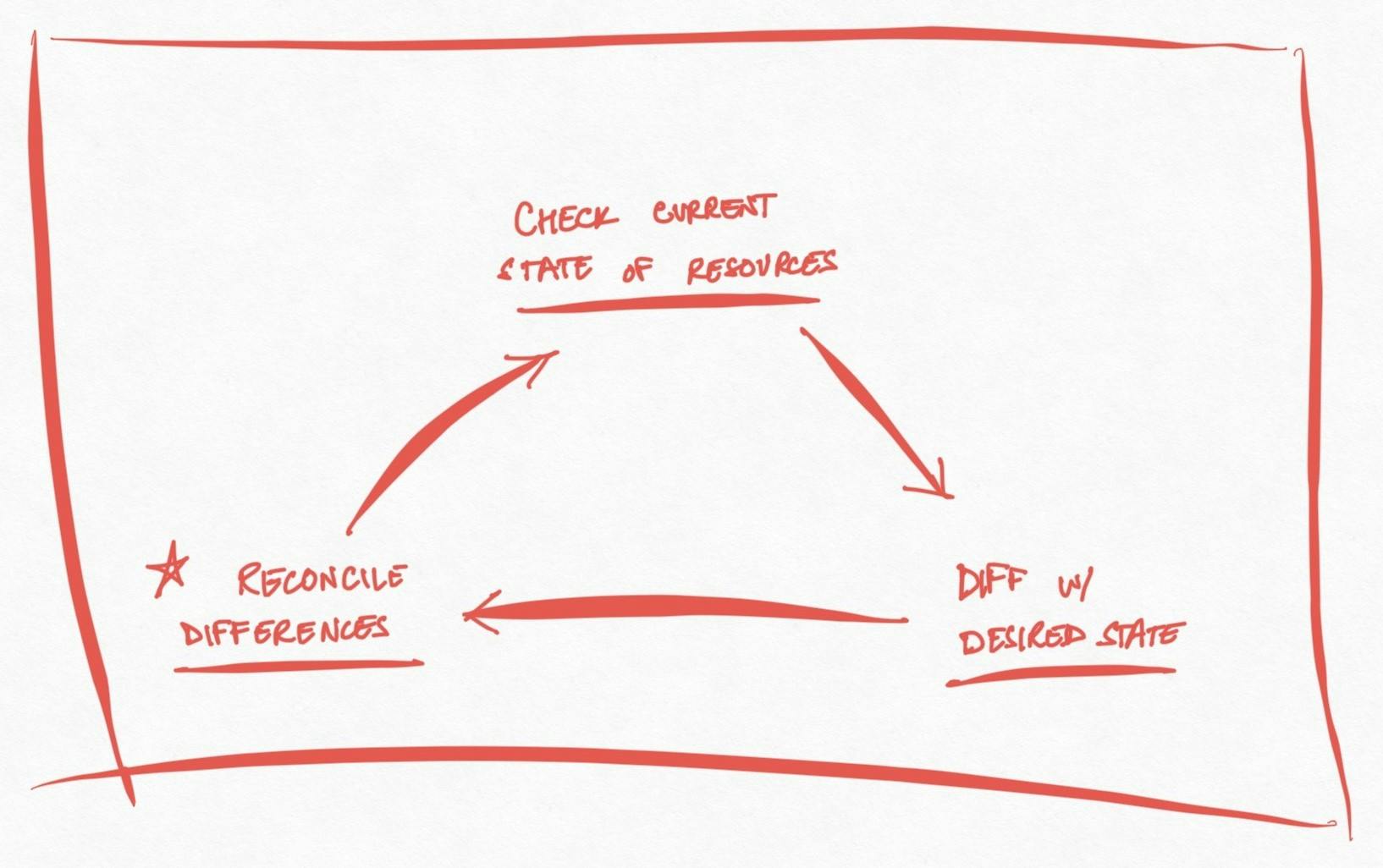
At its heart, Confluent Operator defines custom resources and links them with with a controller running the control loop:
observes the current state of the custom resources it manages,
checks how it is different from the desired state of those resources and
reconciles those differences by changing the current state to match the desired state -> This is the core of the operator.
In Part 2: Confluent's Custom Resource Definitions: brokers, zookeeper, schema registry, etc.
- This post is based not on any confidential material from Confluent, but from publicly available resources published by Confluent.*